Linux PC 2007 ("Blackbird")
This page describes my way to a very special machine, based on a
Zalman
TNN500-AF heatsink case, therefore completely fanless and consequently
almost noiseless (there's still the hard drive, but if you pick a silent one
like a Seagate Barracuda that's not really an issue). Selecting the
right components is a major headache, though, and you can run into all sorts
of unexpected problems, so I thought this page might be helpful to people
who'd like to tackle the issue. Before I start, I'd like to thank Andy Ford
from QuietPC who spent quite some time
answering a lot of my questions before I myself took the plunge, which was
really a breath of fresh air in times of hotline monkeys who can read you
their ten standard answers and nothing more.
Getting the case
The Zalman TNN500 cases are rather hard to get in Europe these days, because
they're not RoHS-compliant and therefore may not be sold within Europe any
more (since about the end of 2006, IIRC). You should still be OK importing
one privately, though, but better check with customs first. You can occasionally
still see its smaller brother, the TNN300 case for Micro-ATX motherboards,
but since I really wanted the full ATX-Tower flexibility, that never was an
option. I still managed to get one of the last cases sold within Europe, but
since I had to decide rather quickly the case ended up standing around idly in
my room for several weeks while I tried to find the right components. I
couldn't find a german source any more, so I went through UK-based dealer
QuietPC, who were also very helpful
answering my question (as mentioned in the introduction). Although it was
just the empty case, I did have some reservations about buying it abroad,
but when I saw the case and how it was packaged these concerns turned out
to be completely unfounded; anyone trying to damage this puppy will need at
least a crowbar. I think apart from shipping costs there wouldn't be any
problems having one sent from the US even. It remains to be seen what Zalman
will do about the RoHS issue. Since it looks like the case wasn't exactly
a profitable business for them, it'll probably be a long time before a
successor appears, if one appears at all. It's a pity, because for truly
silent systems with full flexibility I'm not aware of any alternatives
worldwide (don't get me started on "silent 120mm fans"), but
from a business point-of-view it's understandable.
The case is a very macho affair. Less deep than a regular midi case, but a lot
wider (and heavier, 26kg empty), with two massive rows of cooling fins on either
side. All cases come equipped with 400W passively-cooled PSUs (basically
the PSU has one side of the case entirely to itself to keep it cool).
CPU and graphics card are cooled via sets of 25W heatpipes attached to the
case (6 for the CPU, 3 for the GPU and there's once for the northbridge,
too). The case can thus cool CPUs up to 150W (although over 100W still
requires a fan, apparently to keep motherboard components very close to
the CPU alive) and graphics cards up to 75W. Which dates the case, obviously,
since these days graphics cards tend to draw a lot more juice than CPUs.
And these heatpipes pose a major problem when choosing components, because
attaching these heatpipes to your components requires very specific
mounting holes on said components and whether specific components are
compatible with the case is very hard to find out other than by actually
trying to install them. Zalman do have a list of recommended components
on their website, but that's hopelessly out of date and therefore completely
useless unless you're planning to build an oldtimer. So all you can do
is search the web regarding what other people have used... and hope
for the best.
The components
I like the underdog, so I wanted to go AMD Athlon again; besides, before Intel
released their Core 2 Duo series, AMD was considerably ahead and idle power
consumption of current Athlons is still noticeably better. The best compromise
for me was the Athlon X2 4600+ EE, rated at 65W TDP. That was the
easy part, the real fun began with the motherboard. Fortunately, I found
the End PC Noise site, who sold
TNN500-based AMD systems with an Asus M2N SLI Deluxe motherboard,
which is nForce 570-based, has most of the things you'll need already
on board (including dual Gigabit ethernet) and is a fanless construction
with a heatpipe cooler of its own for the northbridge chipset; OK, I certainly
won't use SLI in this case, but apart from that this motherboard was just about
perfect for me anyway. Probably the biggest headache was the graphics card. The
guys at QuietPC sold a TNN-system of their own (the webpage for their
Jaguar
system should still be up for reference) with an Nvidia 7950GT graphics card,
but the temperature readings (up to 85 C under load) seemed a bit
too extreme for me, so I decided to stay one level below that. I wrote to
several graphics cards manufacturers, asking about their fastest cards
with a TDP < 75W, but the feedback was almost uniformly pathetic (see
"hotline monkeys" above). Try finding out whether a graphics card
has the right kind of mounting holes and whether the factory-installed fan
can be removed without excessive force if you're in a masochistic mood.
I asked Asus, MSI, Gainward, EVGA, XFX and
Gigabyte the simple question about TDP for their cards. I never got
an answer from Asus or XFX, the others did reply but apart
from MSI nobody even mentioned TDP or showed the slightest interest in
actually helping me with my problem. MSI support was by far the
best, they actually showed an interest in my question rather than trying
to weasel their way out with alleged website info that doesn't exist (I haven't
found TDP in the product description of any of these cards). The MSI
support operator actually bothered to ask their technicians and although
the figure he gave me was almost certainly wrong (80 W for the 7900GS?)
I'd rate this as phenomenal compared to what the others tried to get away
with. In the end I just bit the bullet and picked the card right below the
7950GT, i.e. the 7900GS; I really wanted 512MB on board, though, which limited
the choice of manufacturers to Gainward and XFX (IIRC), where I picked the
former due to availability (Gainward Bliss 7900GS, PCI-Express version).
I would have preferred to pick MSI instead because of their support,
but unfortunately they didn't have any 512MB variants at the time, so sadly
bad support won by features. Memory... the motherboard supports ECC and that option
appealed to me, but in the end I decided on regular DDR2-RAM instead, namely 2GB
of matched Corsair XMS2 DDR2-800 RAM. The rest was pretty much standard stuff,
easy to pick: Seagate 320GB S-ATA hard drive, Pioneer DVR-111 DVD writer and
a Teac floppy drive (yeah, I actually think a floppy is still convenient
now and then) and some additional heat-conducting paste. I left out the
sound card for the time being, because onboard sound was good enough for
games and system beeps and for real music IO I was planning to get a good
card once everything else was working, most likely
RME again since I'm
really fond of the Digi96/8 PAD in BlackThunder,
which I consider an almost perfect card (the only thing missing is balanced
analog IO). With all the other components ready for action, the hard work began...
The assembly: oh the pain!
Naturally, we'll start with the motherboard. This is also one of the most
difficult components to install in a TNN500 case because it requires attaching
heat-conducting aluminium blocks on the back of the board where FETs are
located which'll transfer some additional heat to the case. In a regular case,
the case fans will cool these components, but the natural convection you'll
get in a TNN case isn't really enough to cool the FETs near the CPU socket.
These mounting blocks have heat-conducting adhesive tape on either side,
so you won't have the luxury of pushing the board around for a good fit
or you'll losen the blocks or push them onto soldering spots, causing a
short circuit and so on, besides the tape isn't reusable so you can't just
retry a couple of times; it'll have to fit (almost) perfectly the first
time. Therefore you better make sure everything's OK before you fix the
blocks, or you'll need a new set of adhesive pads (or risk heat overload
or shorts, depending on the kind of misfit). In particular, make sure the
CPU cooler can actually be installed. I found out during my dry runs that
none of the CPU brackets that came with the case allowed me to attach the
CPU cooling block to the AM2 CPU socket because the TNN case only supports
socket 939 on the Athlon side. So how on earth did the guys at
endpcnoise manage to install the
AM2 motherboard in the TNN case? An email to their support address was
quickly answered: they've got an adapter for socket 939 coolers to AM2
motherboards which I ordered right away (couldn't find a local source
for something like this); it arrived after a couple of days (extremely
fast for overseas delivery), during which time the whole operation rested.
Right, next attempt. The adapter basically consists of two aluminium bars
which you screw onto your motherboard and which provides the screw holes at
the place where socket 939 coolers expect them, so that's that problem
fixed... or so I thought, until I realized that the screws I got with the TNN
for the CPU cooling block were much too short, so I couldn't attach the bracket.
Since these aren't metric screws, I failed miserably in my attempt to get
longer ones here in the munich area (OK, some shops were also closed since
this was shortly after christmas, but I don't think I'd have had a lot more
success at any other time). So now what? The TNN screws thicken in the
middle and that's where they'll sit on the CPU bracket. In other words,
if you widen the screw-holes of the CPU bracket (only about a millimetre
will do the trick), the screws will be too long all of a sudden; that problem
can easily be solved with a couple of washers, though, so when operation
"longer screws" failed I got a steel drill and some washers instead
and fixed the bracket (another delay of a couple of days while I pondered
the problem and alternative solutions). So now at last the CPU cooler will fit
perfectly... wrong again, but this time fortunately only very slightly. The
problem is that one of the screws also has to fit between two heatpipes and
Zalman designed this so "perfectly" that the slightly thicker part
of the screw is already too much to fit between the heatpipes without strain.
The two innermost heatpipes will therefore end up slightly bent, which'll
compromise their performance somewhat. Not really an issue for me, since the
Athlon X2 4600+ EE CPUs are rated at 65W TDP and the 6 CPU heatpipes deliver
up to 25W each, so even if the two middle ones stopped working completely
(which they certainly won't), I'd still have 100W of heat transfer capacity,
way more than I need. You shouldn't install a CPU with TDP > 100W to begin
with (since that'll necessitate a fan), so it's pretty much a moot point anyway.
However, the moral of the story for me is: if you need the AM2 adapter, I'd
recommend just telling the guys at endpcnoise that you want to use it in a TNN
case and whether they can please include some longer screws; they know the
case and I'm sure they'll do it.
So now, can we finally assemble this goddamn thing? Amazingly enough,
the answer now is yes. So let's devise a strategy for the cooling blocks
first of all. The big problem here is the panel over the rear motherboard
connectors which'll establish a good, "professional" fit of the
motherboard; unfortunately, this panel doesn't stay on the motherboard on
its own accord and you'll need both hands to get the motherboard in the
right place on the first attempt. Solution: duct-tape the sucker onto the
motherboard via its little metal tongues. This really shouldn't be a problem
even if you leave the tape there after you installed the motherboard (you
mustn't attach the tape in such a way that it's visible from the outside, of
course). Use real duct-tape as approved by terrorists, hijackers and other
professionals who have to be able to rely stuff stays exactly where you
stuck it, not some flimsy transparent film for office work and Bob's your
uncle. Once that's done, attach the cooling blocks on the backside of the
motherboard, in particular near the CPU socket and wherever else you see big
FETs on the front. Make sure you stay away from soldering spots and other
places that might cause a short. The adhesive thermal pad doesn't appear
to be electrically conductive, but solering spots may pierce the pad and
touch the aluminium of the block; two of these on one pad and you'll
have a serious problem, so better stay clear from the outset. Another word
of advice: don't use alcohol for cleaning the motherboard. I tried this
carefully at a spot and the protective laquer immediately turned dull,
so I quickly removed the alcohol again (no harm done, apparently, but
clearly not a good idea in the first place). Once the blocks are in place,
make sure the board will fit before removing the protective tape from the
other side of the blocks. I'd also advise to get the screws which held the
CPU cooling block in place in the empty TNN case; these are very long and
also fit the holes for attaching the motherboard, so you can use these to
make sure you guide the motherboard into the right place while still at
a safe enough distance to avoid the thermal pads sticking to the case.
With this approach, I found it pretty straightforward to install the
motherboard without any problems at my first attempt (didn't even need
another pair of hands); just don't rush anything and you should be fine.
The CPU cooler should now be pretty easy to install and you can take
some deserved time to admire this first and most fundamental stage.
Time for some serious problems again. The manual describes how to
install your drives, which basically requires unscrewing some brackets,
mounting the drives on them and screwing the whole thing back in. What
the manual doesn't describe is the fact that these screws might have
merged with the case on a molecular level, at least that appeared to
be the case in my specimen. It's not that I was too weak, the screwheads
were (they could hardly take the insane amount of force you had to apply
to loosen them). After completely busting the first pair of screws in an
attempt to loosen them and liberal amounts of cursing and sweating, I
actually had to resort to WD40, thongs and a hammer! You know that dry,
creaky sound a really rusty screw makes when it finally gives? These
screws made that sound, and it was the sweetest music to my ears; the
only sweeter sound would have been the choking death-rattle of the
moron who fixed these screws in the first place should I ever get my
hands on the motherfucker. The WD40 was probably the biggest factor in
getting them loose at all, and I even managed to remove the busted ones
with the thongs after enough soaking time. If you're running into the same
problems: try to find the looser one of the two screws for each bracket (the
one that Schwarzenegger can open on a good day, that is); if you can remove
that one completely, you can tilt the bracket and that way loosen
the other one. If you can't, apply more WD40 and wait, with a bit of
luck you'll be able to remove all the brackets, which you definitely
should do, at least I really wouldn't like the idea of having to give
the case blunt force trauma when installing a second hard drive one
day. Once all brackets are open, put some lubricant into the holes
to avoid the same problems in the foreseeable future (if you'll have
to remove the drives one day and find out the whole crap is fused
again, you'll be in for some real problems). Why Zalman put such crappy
screws into such an expensive and otherwise well-built case is beyond
me. Is decent steel really too much to ask, did it have to be this
pathetically soft metal screwed in by a lunatic and fused shut by
the ages? Although this episode is now several months past it still gets
my blood boiling and I'm planning to replace all of them with decent steel
screws if I can find good matches (hoping these don't have a really exotic
thread like the CPU screws). In hindsight, I'd recommend opening all screws
(the ones holding the drive brackets as well as the ones holding the
yoke over the PCI slots) before you do anything else, i.e. before you
even install the motherboard; that gives you much more freedom with heavy
tools should you need it. Why the yoke too? Well, Zalman put a metal panel
over the PCI slot section at the back (with holes for the PCI cards), but
if your card has stuff protruding close to the edge (like RME HDSP cards),
you won't be able to insert or remove the card because the panel gets in
the way. The only solution is cutting out a piece of the panel and in
order to do that you have to remove the yoke, so make sure you can open
the screws holding it down as well or you may have to turn heavy tools
on a populated case if you get a new card which won't fit through the
panel's holes. That aside, we're now only left with the northbridge.
The Asus motherboard provides its own heatpipe/heatspreader solution,
but that's designed for air-cooled cases, the heatspreader won't work
in a TNN case. The rear-mounted blocks will take most of the heat to
the side of the case, but it would still be nice to attach the case's
northbridge heatpipe (a single one for a change) to the northbridge.
I didn't manage to do that, since the heatpipe is a bit too short and
the graphics card is in the way, neither can you easily connect the
case's heatpipe with the motherboard heatpipe connecting northbridge
and heatspreader because they're at a very awkward angle against
each other, so this is the one thing I'm not quite happy with yet and
will probably tackle sooner or later, although it doesn't appear to
be a problem at all. Anyway, everything should be in place now and
you're ready for the first power-up test.
Wait, what about the graphics card? I recommend putting it in with its
factory-fitted fan for the time being. Some cards die quickly after purchase,
which is rare but you'll have a far easier time getting RMA if you didn't
modify the card yet. Once the whole thing ran for one or two weeks and
survived some stress tests you can install the case heatpipes and enjoy the
bliss of a completely silent PC while playing Doom 3 at ultra
quality. Because the modification also belongs to "assemble",
I'll describe it right away; but bear in mind that I did it after the machine
had its OS installed and the card had to prove its metal during a Quake 4
single player campaign. The Gainward card is rather big (double-height) with
a cooler to match. The cooler is quite easy to remove, just some screws and
a spring mechanism slightly reminiscent of a mouse trap, and it can be
easily restored should that ever be necessary (e.g. RMA...). The mounting holes
were also in the right place (actually, the GPU blocks provided with the TNN case
are quite flexible and support a lot of screw positions), so this card does
install very well into the TNN case. The modification was unexpectedly
simple -- ironically enough, since I expected the biggest problems here,
but got them with CPU cooler and case screws instead. You'll probably have
to play around with how to spread out the heatpipes so they don't bend
too much, but that's about it. I ran out of Zalman-heatpaste while
modifying the graphics card, though, so it was definitely a good idea
I got additional paste on a hunch. Oh wait, one almost-problem: the motherboard's
IDE-connector is very close to the GPU heatpipes (they'll definitely
touch the cable). So if you need to use the IDE bus (like I do for the
DVD writer), better make sure your IDE cable has some protection near
the connector (most decent IDE cables do anyway). And to put the whole
thing into perspective, the heatpipes don't get boiling hot on the
outside even under heavy use, so the regular plastic protection commonly
used on the better IDE cables should be perfectly fine, but avoid cheap
ones where the data lines are only protected by their insulation.
Ready? Hold your breath and power it up. What a relief to see the BIOS
screen and all components listed correctly after drills, hammers, thongs,
WD40 and enough swearwords to make a sailor blush. This concludes the
hardware section, so what are my conclusions as far as the assembly is
concerned (for views about the finished product see
conclusions, this section only concerns the
assembly)? It's doable for a private Joe, provided you work slowly and you're
prepared to improvise as the need arises. It's highly annoying and an amazingly
large amount of problems can manifest in areas where you didn't even expect
them. If you're planning to build a TNN system yourself to save a couple of
hundred bucks, I strongly advise against it; if you can afford the case in
the first place, this savings really isn't even remotely worth the pain and
is far better invested in someone doing it for you professionally. Things
may have been simpler in ancient times when Zalman first released the case,
their recommended components could still be found outside of computer museums,
GeForce 6800 was top-of-the-line, screws also unscrewed and CPUs used more
power than GPUs, but putting today's components into the TNN case without
a dealer's luxury of having alternatives for everything at your disposal is
very annoying work. If you can find a dealer in your vicinity who'll build/sell
you a working TNN system, go for it and save your nerves. I couldn't,
unfortunately, so I had no alternative but do it myself. I would have
gladly paid more and avoided this procedure, but at least I got the
machine I wanted in the end. If you decide to build one yourself despite
these words of warning here's a final one: be aware that you might have to
buy components twice, be it because they turn out to be incompatible (if the
IDE connector on my motherboard was shifted by 1cm, it probably would have
blocked off the GPU heatpipes completely; heatpipe blocks may not be
attachable to CPU/GPU) or because you killed one (heatblocks on the backside
of the motherboard in a position that causes a short or a makeshift
"solution" for a bad heatpipe fit backfires and overheats something).
If this sort of thing will rip a crucial hole in your budget, don't even
think about building a TNN system. Don't think experience in building a
conventional air-cooled system will be much help either, you really can't
compare widely standardized, orthogonal air-cooling (components can mostly
be seen independent of each other) with very specific, interdependent
cooling in a TNN case. I think I was lucky as far as my components
were concerned, except for the northbridge I could attach all of them firmly
to the heatpipes and the temperature readings
confirm a well-cooled system. It wouldn't have taken much to turn this
completely on its head, though.
AMD64 Gentoo, or "the pain continues"
After the Debian Woody debacle (three bloody years without a major release)
I was rather desperate for something less backwards and more flexible.
It wasn't just the age of the packages that was annoying me but also the
dependencies forced on me by some distro maintainer which may make me
install all sorts of other crap I don't need although the package I
really want could easily be built without these dependencies (I took
Debian packages from unstable, relaxed dependencies and built them for my
Woody system on more than one occasion). With binary distributions, the
only thing you could do about this would be a distro flexible enough to
offer you alternatives for most of their packages and ideally a multi-layered
architecture that allows you to install packages in various layers (e.g. a
layer for bleeding edge stuff that may be very dependency-hungry and potentially
unstable, a layer for regular "stable" packages, a layer for
ultra stable, "has to work at all times no matter what" packages
with minimal dependencies and so forth, with the possibility of having versions
of the same program/library simultaneously in all layers). I don't know a
binary distro like this, and since this is the open source world the
easiest way to get this kind of flexibility would be to use the source. Which
leads us to Gentoo Linux. On paper, it all
sounds pretty nice: you can define your own dependencies via your USE
flags and build your binaries automatically according to these settings,
plus Gentoo is pretty much bleeding edge and always among the first to
add new packages. So I downloaded the LiveCD 2006.1 for AMD64 and gave
it a go.
Initially, I was pleasantly surprised: the system booted straight into a
Gnome environment without hassles and all my components were
recognized out of the box, including my USB mouse (I didn't check sound,
since I couldn't have cared less at this stage). So I tried installing
Gentoo on my system (my first with Gentoo, so far having only experience
with Debian and some classic Unix systems). And that's when surprises
turned considerably less pleasant. I had the choice between stage1/2/3
installs, and since the documentation was rather nonexistent (unless you
count reading all documentation on the Gentoo webpage, which, let's face it,
is a bit too much to ask from new users, even ones fanatical enough to give
a source-only distro a try), I just tried stage1/2 first. Bad idea, didn't
work. So I entered this in
Gentoo bugzilla as BUG-159795
and got the reply that stage2 was currently "a tad broken", but
since stage1/2 installs were to be removed soon anyway, this wouldn't be
fixed. Oh lovely, then why the hell is this option still available on the
latest (at the time) LiveCD? OK, next attempt: stage3 installs, as
the other options were apparently ruled out. So I started the stage3
installs using non-binary packages and all ran OK for quite a while
but then aborted while building libusb. So another Bugzilla report,
BUG-159992, which basically told me to install manually. OK, so at this point
it could no longer be ignored that the LiveCD was almost completely useless.
One more try: stage3 install using binary packages -- although an utterly
pointless configuration, since if I wanted a binary distro I'd have
picked one in the first place. In keeping with the LiveCD quality hitherto
experienced, this too aborted installation, IIRC in xclock or
something equally "critical". You'd think the installer could
tell a critical error from a minor glitch, but unfortunately it just
breaks, sends hours of emerging down the drain. In addition, the log
window was so badly programmed that it was almost impossible to select
anything in order to paste it into a bug report or anything (probably
not a coincidence), because the window polled for new output a couple
of times a second and cleared the selection, regardless of whether there
was new text or not. The only solution was being very quick in clicking
on "Select All" in the window menu, followed immediately by
CTRL-C (for copy-to-clipboard). Anyway, the conclusion is quite obvious:
the LiveCD installer is a completely useless piece of garbage. Well, OK,
you can use it to partition your drive, but that's it, really. That still
makes it one of the biggest pieces of crap I've ever had the misfortune to
come across.
Right, final attempt: manual installation as described in the
Gentoo handbook.
This actually worked as described, at least up to the point where you get
a system that's actually bootable so you can scrap this piece-of-crap LiveCD
and speed up your process by orders of magnitude. One of the many annoyances
of the failed attempts to get a stage3 install out of the LiveCD installer
was the download of the stage3 tarball every time you gave it another try,
so if I wanted to avoid downloading this 130MB tarball every time (on a 2000Mbps
DSL line at the time) I actually had to have a second machine running which served
the tarball locally. But as soon as I tried to emerge my system, things ceased to
work as described again because apparently Portage, the Gentoo package
manager, is unable to resolve circular dependencies caused by USE-flags. I had
specified a rather huge number of packages in my USE-flags because I was sick of my
rather dated Debian system at the time, so I had a few of those. Like lots of packages
depending on Doxygen because I had added doc to my USE-flags,
but Doxygen itself depended on lots of these packages (directly or
transitively), so it wasn't possible to emerge my system that way. I had to
identify crucial packages by hand and try to break their dependencies by
reducing the USE-flags for these packages. Another classic example was that emerging
xorg required some OpenGL includes provided by Mesa, but
Mesa in turn depending on xorg, resulting in a dependency deadlock which
forced me to work in the console all the time (or have another machine running
and working via ssh). The reason was that one Mesa plugin depended
on xorg for mode switching or something, so I emerged Mesa
without X support (USE="-X" emerge mesa), which then
finally allowed me to emerge the X window system and leave the console.
I got the whole system up and running that way eventually, but it was
certainly much more work than I had anticipated, the blame for which rests
firmly on Portage. It also took me a while to activate the device-mapper
for encrypted home and swap partitions (so far I had used the cryptoloop and
not the device mapper); in part this was due to the sparse documentation about
this, plus some downright wrong examples on the net (physical and mapped devices
swapped), and I also got the hash algorithm mixed up at some point, but I did
get it to work eventually. The problem of the circular dependencies still doesn't
bode well for Portage: a package manager must be able to deal with
this sort of thing by automatically building packages with reduced USE-flags
to break the dependency graph, then building them again with full flags afterwards.
It's really a travesty that the user is left to do it by hand (and possibly
forgets to rebuild packages with full USE-flags afterwards, which happened
to me with emacs). The package manager could do a much more efficient
job of it too, by identifying the minimal set of flags and packages
causing the dependency deadlock, something you'll hardly manage on foot.
But I can live with this sort of thing if it pays off later when maintaining
the system. I'm used to the fact that Unix systems are a bitch to install
in such a way that they do everything the way I want them to (which is
a lot more than slapping a bunch of standard packages on the system and
calling it "finished"). So what about Gentoo in use? Well, the
first couple of rounds of emerge --sync; emerge --update world
went fine, but the sheer volume of updates (barely a week below 50MB) pretty
much rules out Gentoo for anyone without flatrate DSL (which I have, but it's
still worth mentioning). I also frequently got an absolute shitload of new
config-files in /etc that needed updating; initially, I tried to deal
with this by hand, which I really wouldn't recommend for two reasons: 1) it's
tedious and 2) the likelihood of mistakes is very high and unless you
did a very good job of keeping track of your changes you may end up
with a severely compromised system. This happened to me because for some
reason (which I can't for the life of me reconstruct) I ended up with a
/etc/init.d/net script which was identical to /etc/init.d/net.lo
and caused the system to hang during boot. No feedback why it hung, nothing
in the system logs, it just hung (probably trying to parse the device
from its filename (lo, eth0, ...) and not being able
to cope with an empty result). I found out how to still boot the system
via CTRL-C followed by interactive boot mode and tried to fix the problem
for weeks before I was finally able to track the cuplrit with the aid of
Gentoo Bugzilla (yes, something positive to say about it at last). Based
on this experience, I strongly recommend you use dispatch-conf
with a database of changes in the background. Why this system isn't
part of the standard emerge cycle is beyond me, though. And there's another
"tool" which really makes you question the sanity of the
Portage designers: revdep-rebuild. After some updates,
I suddenly found that a large number of programs on my system weren't
linking any more because of a missing libdbus. Apparently this
lib had wandered into glibc (or had been taken out, I can't
remember the details) and anything linking against it ("only"
about all the Gnome stuff, nothing serious) was no longer working.
At another occasion, some lib had its version numbers upped and of course
everything linking against the old lib didn't work anymore either. When
I first came across this effect, I manually rebuilt some crucial libs
and got things working again, but come on: you use the package manager
to update your system and it becomes inconsistent in the process? Later
on I found revdep-rebuild which automates this process, i.e. it
looks for reverse dependencies, packages that need rebuilding after the
libs they depend on changed, and re-emerges the packages in question. Which
is nice and all, but offering this as a separate tool rather than something
built into the very core of the package manager where it rightfully belongs
is outrageous! What's the Gentoo philosophy here, pray tell? "We update
your system, but consistency is optional"? Sorry folks, but what
revdep-rebuild does is not optional, it's the most fundamental
functionality a package manager must provide: keeping the system
consistent at all times. Without that, I might as well scrap the package
manager altogether and do everything by hand. ATM (May 2007) I can only use
revdep-rebuild partially because unfortunately it has a bug that finds
bogus linking problems in GCC (BUG-125728/179239) -- and since GCC takes over an
hour (!!!) to build on this not exactly shabby system (probably twice the normal
time since it's a multilib installation), it's really out of the question to
just rebuild it on the side, so I can only use it to gather stats in
--pretend mode. And isn't the difference in numeric values of these
two bugs rather suspicious? Yes, if you look at the dates you'll notice that
this bug has been known for over a year now, and still hasn't been fixed.
Some people tried to solve it via symbolic links, but with mixed results.
Speaking of GCC: currently the ebuild only uses one parallel thread and
therefore wastes massive amounts of CPU resources on multicore systems (i.e.
pretty much any up-to-date machine); BUG-179240, but again nobody seems to
give a damn. So amongst other things a vital (and bizarrely enough external)
tool of the Gentoo package system has been compromised for over a year and
apparently nobody at Gentoo cares; jolly good, fellas, I think I'll pick
something Debian-based again for my next machine.
Then, just when I felt comfortable with the system again, something really
irritating happened: after a large update involving X-libs and a new X-Server
(xorg-server-1.1.1-r5) I did on the weekend of 7/8 Apr 2007, I started
Wine to continue my Far Cry game and
all of a sudden tree textures at a distance were completely screwed up (an engine
optimization which apparently reduces the distant trees to just a rectangle with
a transparent texture, which becomes inactive when you get closer). I tried
different Wine versions and all of a sudden the real bummer: right on launching
Wine, the screen turned black and the system was completely dead, not even
ALT-CTRL-F1 worked any more, only ALT-SYSRQ-[SUB] still worked (no blinking LEDs,
though, so apparently not a kernel panic). Nothing in the system logs, just regular
messages and then my SYSRQ-keypresses all of a sudden. I tried again and got the
same result when I repeatedly ran Wine and Far Cry: it usually worked the
first time, but then it'd total my machine. I'm pretty sure it only happened with
Far Cry and not some other, equally shader-intensive games like
Max Payne II. Nor were there any problems with native games, hours
of Quake 4 produced neither crashes nor texture/shader bugs (so hardware
defects were pretty much out of the question). I tried emerging xorg-server
from the command line rather than an X environment to be on the safe side, but
that didn't fix it either (it goes without saying that I always end my X-session
and start a new one after emerging a new X-server, or after a large update involving
X-related libraries). Temperature had nothing to do with it either, since
the system was usually quite cold when these crashes occurred and they happened
either right at startup or not at all. So I downgraded to xorg-server-1.1.1-r4
on a hunch and lo and behold: no more crashes, but tree textures in Far Cry
remained screwed up. The following weeks saw massive updates to X-libs and
also an update to nvidia-drivers, none of which changed the Far Cry
texture bug. Then, on the weekend of 5/6 May 2007, there was another huge update
involving X stuff, which unfortunately removed xorg-server-1.1.1-r4
from the portage tree, so I had the choice of trying xorg-server-1.1.1-r5
once more or downgrading to xorg-server-1.1.1. In the light of the
massive updates of previous weeks, I decided to give r5 another try
and guess what: 1) no more crashes and 2) the tree textures in Far Cry
were perfect once again. Can anyone explain this to me? How can one system
update cause drawing errors and complete system crashes in one specific program
(Wine with Far Cry), while everything else I tried still worked fine,
a downgrade of the X-server cure the crashes but not the drawing errors and
a later update involving the exact same X-server which previously crashed the
entire system for this program now not only not crash (which could be explained
with the update of nvidia-drivers, I guess) but also miraculously cure
the drawing errors all of a sudden? At this time, I was quite familiar with
revdep-rebuild, so the system was consistent at every stage as far
as system tools allowed me to know. So what was going on here and how likely
is it to return? Was it a bug that only manifested with the older nvidia-drivers
and the newer xorg-server? Clearly, xorg-server-1.1.1-r5 in
itself wasn't the cuplrit since it didn't crash when I installed it the second
time. Was there a problem in the 64->32bit emulation layer I have to use to
run Wine? As far as I can see, the 32bit-X-libs haven't changed in months.
I think I can comfortably rule out hardware defects since a system surviving
torture tests like hours of Quake 4 or huge compile jobs during system
updates without the slightest problems is fine on the hardware side. Either
way I turn this problem, I can't make heads or tails of it and it's making
me rather uneasy. Any way I turn it, I notice an interconnectedness that's
rather unsettling. Maybe it was a one-off problem I'll never see again, but
if it wasn't... Basically, I still don't feel really comfortable with Gentoo
at this stage. Maybe I just picked a bad time, especially for the AMD64
branch, but so far reliability isn't quite what I expected; Debian was a
lot better in this respect. It's still too early for final thoughts on this
matter, though, I'll wait another couple of months before I do that. So far
it was definitely a lot more work than I expected, and a lot more work than
necessary due to totally broken LiveCD installer and vital package manager
functionality offered as "optional tools". Let's leave it at that
for now.
RME HDSP9632: more pain on the way
A machine like this is of course perfectly suited to serve audio files (although
it's severely overspecced just for that, of course, but I never said I wanted
to use it just for that). I'm very picky about audio quality, though, so I
certainly wouldn't accept a card that doesn't have native support for all
standard sampling rates, which rules out pretty much all AC97 chipsets which
are usually stuck at 48kHz and often have very bad resampling algorithms
(e.g. SoundBlaster Live). There are of course much cheaper alternatives than
RME that will give you great sound, but
there are usually small things that annoy me on those. For instance the popular
M-Audio Audiophile range of cards lacks optical S/P-DIF ports and the
electrical ones don't offer galvanic insulation; as someone who was rather
plaged with ground loops and less traceable ground-related noise, this is
completely unacceptable to me, and adding a converter or transformator to make
a new card usable is not what I consider a "solution" either. Contrast
that to RME cards which have both optical ports and galvanic insulation on the
electrical ones and there's just no contest. I've used a Digi 96/8 PAD
card in my old PC for years and am very satisfied with it, the only thing that's
missing is balanced analog IO, but apart from that it's a perfect card.
Unfortunately, this card is out of production and has officially been replaced
by the HDSP 9632 card belonging to their Hammerfall DSP series
of pro audio cards, a much more powerful, complex and somewhat more expensive
card than the Digi96-series. So essentially totally over the top for my
current needs, but the HDSP 9632's multichannel capabilities hold a
certain appeal; I wasn't planning to make use of those right away, but in
the long run this would make multichannel audio with digital outputs and
optional digital room correction for all channels a reality; the only
AV-preamps I'm aware of that offer both are by
Meridian and
TacT Audio, both at insane prices
and only TacT offering true room correction, really. I don't know
if I'll ever tackle that project, but it's certainly nice to have the option.
The HDSP 9632 also has some other nice properties like balanced
analog IO and massive extensibility, so I just ignored the rather hefty
price tag and got me one of those.
Well, the fact that the last posts regarding this card on the
Alsa project homepage were about three
years old, thus even predating Alsa 1.0, should probably have made me suspicious
from the start, but I thought they'd at least bother to post additional problems
that popped up since then... looks like I was asking too much here. Anyway, I
couldn't get the card to work, or much more annoyingly: some bits of it appeared
to work, but none of them correctly. For instance I could record from the digital
inputs, but recording lasted twice the amount of time I had specified and
playing back the recorded signal (via the working onboard sound) played everything
twice as fast; when I tried to play something, the sound was played at half speed,
but nothing could be heard. The additional programs hdspconf and
hdspmixer frequently mentioned as part of the alsa tools/utils packages
were nowhere to be found in my corresponding Gentoo packages either and the
sources I downloaded didn't compile without modifications. When I ran them,
they did recognize the card and displayed a lot of info about it (including
noise of the analog inputs around -110dB and level of active playback channels),
but no matter what buttons I pushed in hdspmixer, I got no sound out of
the card. The main problem here is that the HDSP cards are highly complex
to configure due to their internal mixer matrix, so if you misconfigured that
(easily done), you won't hear anything. Plus one of the pages describing usage of
the card under Linux mentioned the card providing an odd interleaved audio format
that few apps understand, so considering there were no problems reported on the
Alsa page and the half speed effects I described above, you tend to think you're
doing something wrong rather than blaming the driver. When I still hadn't
managed to get the card working after several months (games were a considerable
distraction on this wonderful new toy, I admit, so I didn't spend that
much time on the card, really), I searched the web again and eventually found a
document mentioning firmware incompatibilities; add "firmware" to your
web search string and you'll start to find the relevant pages which had up to
then been buried in static. The gist of it is: firmware versions newer than 1.51
are unsupported by Alsa and cause the bizarre effects I described above.
All cards currently sold have firmware 1.52 or newer and will therefore not
work at all under Linux. The cards can be flashed down via the
legacy
firmware archives on the RME webpages, but flashers are only available for
Windows (fut_win_dsp.zip) and Mac. It is therefore impossible to get
current HDSP 9632 cards to work on Linux without physically putting the
card into a Windows/Mac computer and reflashing it there (and to avoid making
things too easy, using the flasher requires installing the HDSP drivers first,
at least on Windows); these cards must therefore be considered unsupported under
Linux. The fact that the Alsa project page doesn't mention this "tiny"
problem with a single word (at the time of writing, may 2007) is outrageous! So
after I had wished the pox on the responsible Alsa maintainers, I grumblingly
went in search of a Windows machine and reflashed my card. This fixed the issues
mentioned above, so I can now finally record and play back with this card.
I still have a lot to learn about the mixer, though; I'll continue this section
once I know more.
Temperatures (the pain takes a break)
OK, so here's the crucial question: does the case provide adequate cooling for
these components? It took a while until I could actually do these measurements
because kernel 2.6.19 is required to read this motherboard's temperature sensors
via the lm_sensors package and it was several months before that kernel was
rated stable in Gentoo (actually, I went right to 2.6.20). The graphics card is easier,
you can read the core temperature via nvidia-settings. In case you're not
aware of it, this program also has a command line interface so you don't have to run
a GUI app just to read temperatures and more importantly you can actually log
the temperatures into a file in the background (making statements about temperatures
by reading the output of some GUI program is kid's stuff, totally ridiculous);
the command to read the GPU core temperature is nvidia-settings --query=GPUCoreTemp,
BTW. What I did was write a little script that polls the motherboard and GPU
sensors every N seconds and logs the time plus the temperature readings
into a file (it's rather motherboard-specific, so I don't think there's much
point publishing it, but in case you're interested let me know). I then just
started this script before I put the system under load and thus got my readings
without having to break the load even for the shortest amounts of time. Initially
I just looked at the textual output, which looked quite usable, although the sensors
are obviously rather crappy and consequently temperatures jump around a lot. When
I started converting these readings into graphs, it became apparent that some
sort of smoothing would be required, or at least highly desirable if I didn't want
to end up with one extremely thick and frayed "line" per sensor. Since I didn't
take this into account when I did most of my measurements (and quite frankly I'm
too lazy to repeat them now), time resolution was a bit coarse (5s) to allow for a
lot of averaging, so I only averaged over 4 values in most cases. The final
measurements were for the first game I tried on this machine, Quake 4,
and those I did with 1s resolution, allowing me a much higher averaging value
without sacrificing temporal resolution. Ambient temperatures for all of these
measurements were "normal" temperatures for central-european spring,
ranging from around 15 C to close to 30 C, depending on time of day and general
weather conditions (bloody hot again at times this year). If you stress the system,
the case does get warm, but nothing that could even remotely be called hot. Even
if you put full stress on CPU and GPU, it barely reaches body temperature by the
feel of it. Amazingly enough, the same goes for (the exterior of) the heatpipes and
the aluminium blocks attached to them. You'd think they might get blisteringly hot,
but not even close; the heatsinks of the passive-cooled GF4400Ti I had in
BlackThunder for a long time got a lot hotter
under load. I sometimes removed the back panel next to the PCI slots, which allowed
me to reach inside and touch the GPU block, and even after massive stress on the GPU,
these were never even uncomfortable to touch (and yes, the GPU block has bloody
excellent contact to the die, as can be seen by how quickly the core temperature
drops as soon as you remove the graphics load); the same goes for the CPU blocks
connected to the case. The air in the case doesn't get particularily warm either,
but remains very moderate all in all, I've experienced considerably more heat in
air-cooled cases where the airflow wasn't exactly perfect and the fans did a
better job of spreading the heat throughout the case rather than getting it as
fast as possible from the hot components to the outside. Ambient temperatures appear
to have little effect on CPU and GPU core temperatures, but I noticed they do
have an effect on the northbridge readings. If the room is cool, the northbridge
temperatures are usually around 5 C below the CPU temperatures even if you put
the CPU under load; with higher ambient temperatures, this distance
shrinks as the CPU gets hotter. I never measured more than about 53 C for
either of them even under the most extreme conditions, however, so I don't think
there's anything to worry about here. And finally, convection: if the system is
heated up and you put your hand under the case near the bottom ventilation grille,
you can feel a slight draft, as natural convection sucks the cooler air from the
ground through the case and out again at the top. It's not as strong as a fan,
of course, but it's actually stronger than I expected and should easily suffice
to keep those components not connected to heatpipes in a refreshing breeze. In
order to maximize the flow, I recommend raising the two grips at the top of the
case (meant for lifting it); it won't do miracles, but I think it increases the
throughput a little.
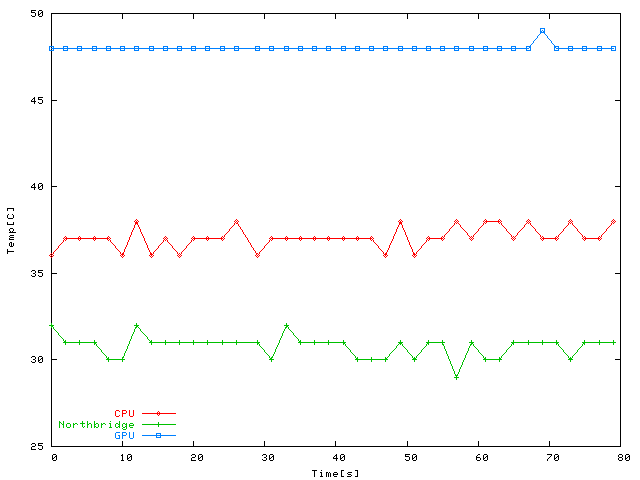
Idle temperature readings, not terribly much to see here. No averaging, so you
can see the rather erratic jumps of the raw sensor data. GPU is much hotter than
the rest of the components, but as far as I know this is perfectly normal for
this generation of graphics processors.
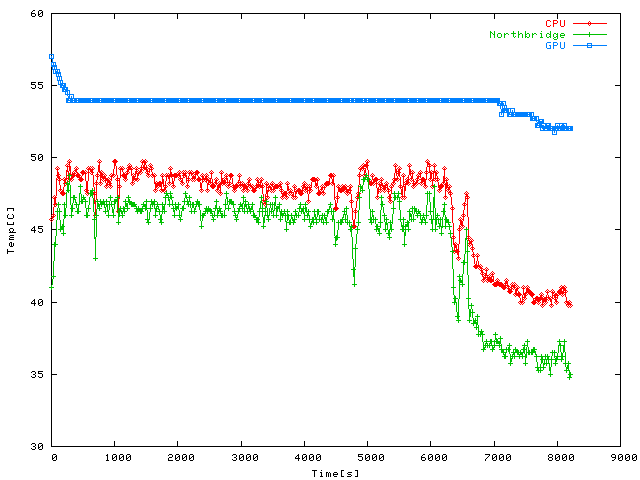
Temperatures during a long emerge --update world session (involving GCC
again) followed by a half-hour cooling stage (basically leading to the idle temperatures
in the first graph), averaged over 4 values. The log doesn't start from idle
temperatures, I measured this shortly after a Far Cry session. Even during
this huge sequence of compile jobs, the CPU doesn't go over 50 C.
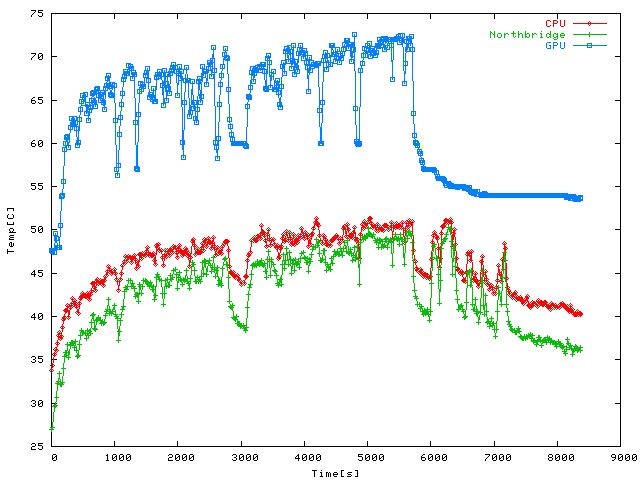
Temperatures during a 90 minute session of Quake 4 (Ultra Quality at
1280x1024 resolution), using the SMP client. Values were sampled with 1s resolution
and the plot shows the averages over 16 samples. Sudden drops in GPU temperature
are times spent in the main menu or the loading screen between levels (I had a short
break around the 50 minute mark, obviously). The CPU doesn't go over 50 C in this
case either; GPU core is much hotter but still way below its critical limit, plus
it drops to 55 C almost immediately as soon as you leave the game, only the further
drop to its idle temperature a little below 50 C takes a considerably longer time
(classic exponential curve, basically). After 90 minutes I had reached my most hated
part of the game, the rail-shooter where you have to take out the missile launchers
while the driver jerks you around to make sure you always hit air at the crucial
moment, so I figured this was a fine place to call it a day. In case you're wondering
what the CPU was doing after 100 minutes all of a sudden: I emerged a couple more
packages, but continued the measurement nevertheless since I consider the GPU
temperatures to be the most important aspect of this measurement.
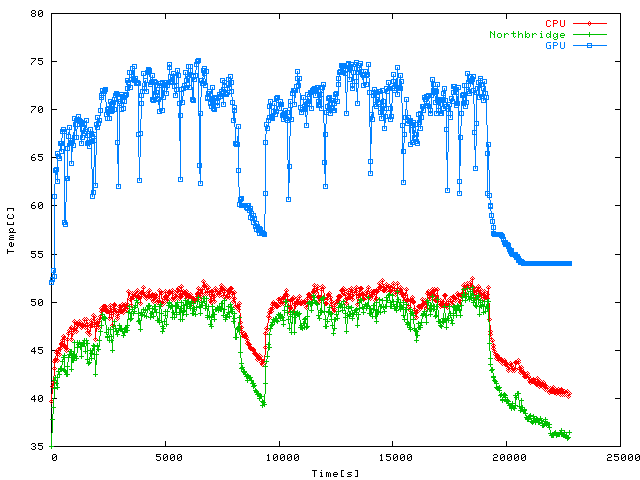
The continuation of the Quake 4 campaign started above, in a giant > 5 hours
session which took me from the hated rail-shooter to the end of the bit where you clean
out the basement of Iron Maidens and other Strogg vermin. Settings were the same as
above, but averaged over 32 sensor samples. Ambient temperatures very pretty hot that
day, so this time around the GPU does reach 75 C, the CPU goes to about 52 C and the
cooled down temperature is a little higher than usual as well. Still pretty good
readings, IMHO.
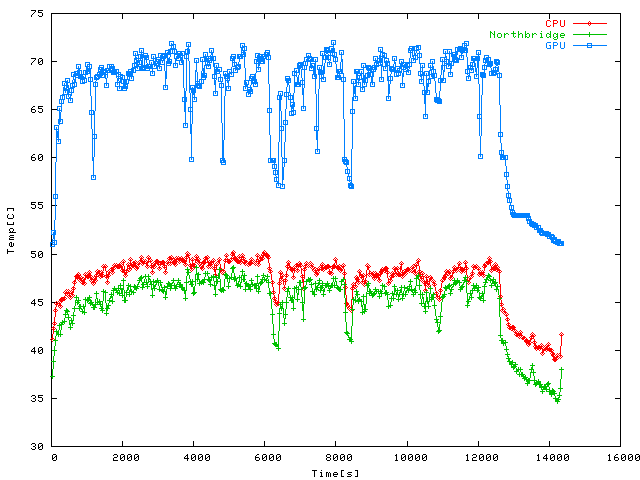
And finally, the ending of this Quake 4 campaign, from the basement assignment
to a busted brain in another 3.5 hour session. Settings the same as in previous
Quake 4 readings, and again averaged over 32 sensor samples. Ambient temperatures
were considerably cooler this time (what a relief, I hate sweating my butt off all day),
so CPU and GPU stay about 2--3 C cooler than in the second session. Hmm... adding my
playing times, that's around 10 hours for all of Quake 4; not bad by my standards,
considering I wasn't attempting a speedrun or anything. Maybe I should play through
Doom 3 again some time... just in the interest of science / temperature
readings, of course ;-).
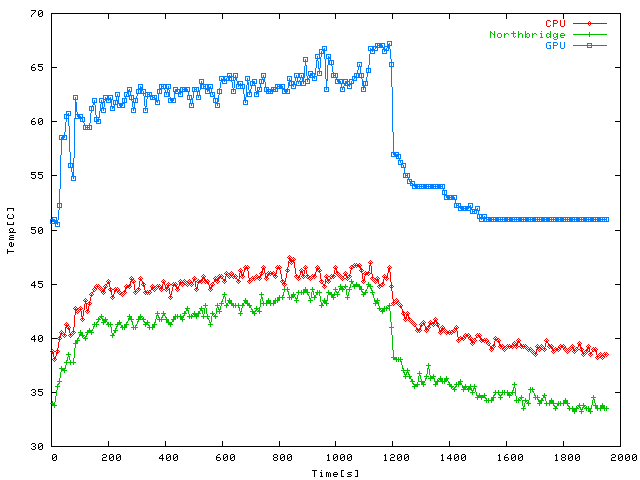
Temperatures during a 20 minute session of Unreal Tournament 2004, including
a 10 minute cooling down phase, averaged over 4 samples; playing resolution was 1600x1200.
Note the GPU temperature is considerably below that of Quake 4, although I had all
quality settings pushed to max. Everything else is as already seen above.
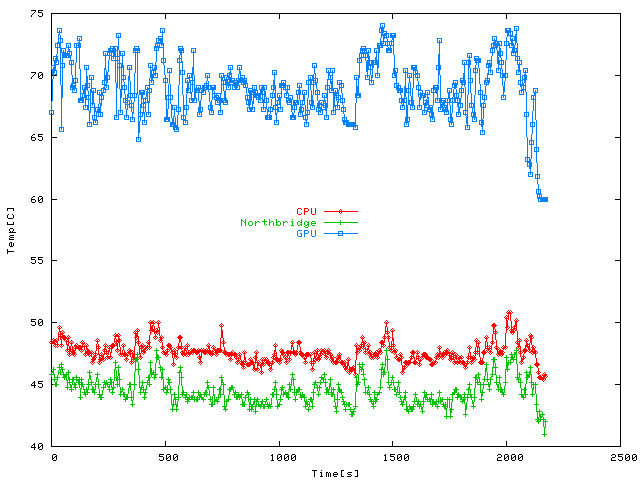
Temperatures at the end of a longish session in the 3rd party level Trite Breeding Factory
for Doom 3, at ultra quality in 1600x1200 resolution, sampling the sensors every
second and averaged over 10 seconds. I had forgotten to write this to a logfile, so I had
to grab it from the console, hence I only got the last 40 minutes or so. Ambient temperatures
were rather hot, so the GPU peaks around 74 C at times, but it averages out around 70 C,
and the CPU appears to have little to do all in all. Funny how time passes, the Doom 3
engine can hardly be called demanding any more even at ultra quality.
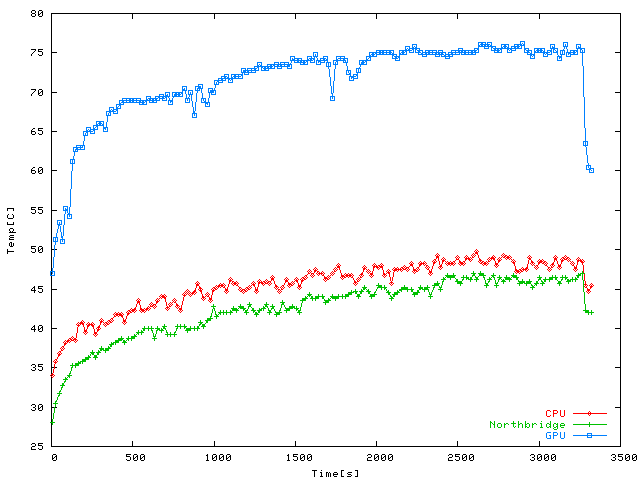
Temperatures during an hour-long session of Far Cry under Wine (versions 0.9.33
and newer, IIRC), averaged over 4 samples; playing resolution was 1600x1200. Note that
the shader-heaviness of this game reflects in the GPU core temperatures which are a
good 5 C above those on UT2004, even higher than the ones for Quake 4, which is
particularily interesting since there's emulation overhead in this case that doesn't exist in
Quake 4 and Far Cry actually predates Quake 4. The breathtakingly
delicous looking water comes at a price, apparently, but boy is it worth it! I cut
the cooling off sequence early, but as you can see it takes the same plunge as
previous measurements.
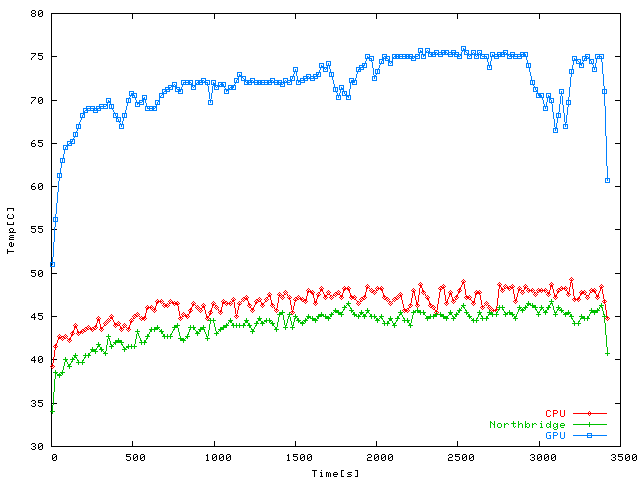
Temperatures during an hour-long session of Stubbs the Zombie under Wine,
again averaged over 4 samples and using 1600x1200 resolution. Pretty much the same as
Far Cry, this game is very shader-heavy and pushes GPU temperatures up to 75 C
while the CPU doesn't even scrape the 50 C mark.
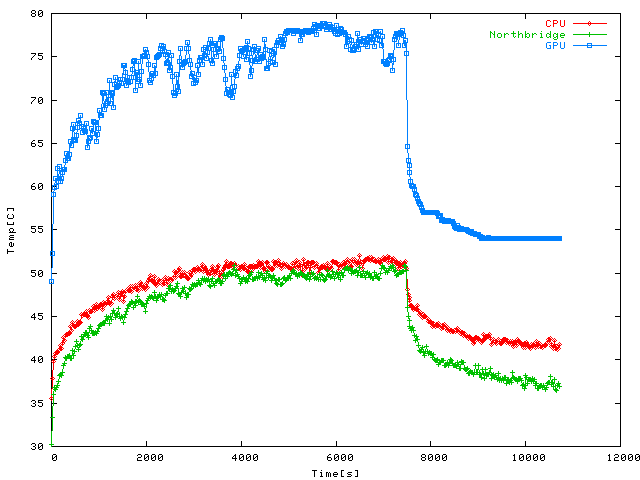
Whoa, we peaked! This is the log of a two hour session of Stubbs the Zombie under
Wine at 1600x1200 resolution, sampling sensors every second and averaged over 20 values.
It was pretty hot again when I did the measurement and this time the shaders really pushed
the GPU the furthest I've seen it so far, up to around 79 C. The remarkable thing here
is that the temperatures show exactly the opposite of what you'd expect in an emulated
game (high CPU load due to emulation overhead, low GPU load because the emulated machine
can't feed the GPU as fast as a native one). But here the CPU appears to be doing less
than in Quake 4 and it's the GPU that gets the thorough workout. Looks like most
of the game is running on the shaders. In case you're interested: the session started
with Stubbs getting his first tank and ends with about the tenth futile attempt to
put an end to Andrew Monday (but fear not, in a second session later that day I
finally cracked that nut, and a bloody tough nut it was).
Conclusions: I think temperatures are fine, if not excellent. GPU core temperature is
maybe a bit higher than I anticipated, but modern GPUs are designed to take a lot more
heat than CPUs and considering I'm still 5-10 C below the readings of QuietPC's
7950GT card and nvidia-settings reports the critical temperature for this card
at 135 C, I guess I have more than enough headroom. These temperatures appear to be
perfectly normal for this generation of cards, as confirmed by a measurement for a
bunch of 7900GS cards done by
AnAndTech. The
idle temperatures for their cards ranged from 49 C to 55 C, load temperatures from 63 C
to 73 C, which is roughly how my card behaves. Exact comparisons are hard to make
because a lot of relevant information is missing, for instance ambient temperatures which
can have an impact on idle temperatures in particular. Then what's your definition of
an idle measurement? One where the entire system is idle or one where only the graphics
card is? In the first case, my card is cooler (at 48 C, see first graph) than any of the
ones AnAndTech measured; in the second case, it's still doing OK (at 54 C,
see second graph). Then there's load... they measured a special demo for a mere
5 minutes and claim this was representative of long gaming sessions, which I have
rather serious doubts about. Games like Far Cry, Stubbs the Zombie
or Quake 4 don't give the GPU much of a breather either and even if I add
about 2 minutes loading time at the start of my measurements, you'll see that my
card is still barely touching 70 C around the 420s mark. They don't mention whether
there were any delays (however small) between the end of the stress test and the
temperature measurement and whether they did any averaging or just picked whatever
value the sensor showed. Considering that my measurements were much more thorough
and longer than theirs, I certainly won't waste any sleep over being a coupled of
degrees hotter after 5 hours under real-life load than their hottest card after 5
minutes worth of synthetic tests. Anyway, I never experienced any temperature-related
instabilities, the only crashes I had with this system were the ones I described at
the end of the Gentoo section and those happened regardless of
system temperatures. I suppose I must have done something right after all.
Preliminary thoughts and conclusions
So after all this work and money spent, what are my current views about the system?
Well, I didn't expect this to be a smooth ride, and I had those expectations
confirmed. But at this time I can safely say I got what I wanted: a fast, stable and
essentially completely noiseless PC, and in contrast to the offerings of companies
like Hush PC with the full flexibility of an
ATX tower and far fewer restrictions concerning room and power consumption. Now I
know there'll be a lot of kiddies who'll claim they can build a "noiseless"
system for far less money using their beloved 120mm fans and so forth. I've read
countless claims about this and that being "unhearable" when I know from
practical experience with the same or better components that this simply isn't
even remotely true. Even if the fans get extremely quiet, there comes a point when
the airflow around cables and grills itself becomes a source of noise, and although
it's a far less annoying noise than the high-pitched whirring of a cheap fan it's
nevertheless audible in a quiet room, and that's my benchmark. I seriously doubt
the fan noise levels quoted by fan manufacturers were measured with the fan built
into an actual PC case (where it usually blows on or around something, which
naturally generates additional noise) rather than free-field to make their stuff
look as good as possible. I, however, would like to have my PC truly
inaudible even at 3am with windows closed during the pianissimo part of a classical
recording, i.e. a situation where you really don't need a bat's hearing to
literally hear a pin drop at the other end of the room. Most people will be far
less picky and that's fine, but that only means "this doesn't bother me"
rather than "this is noiseless" and I really couldn't care less what bothers
other people or not, only what bothers me. I have a pretty quiet system for
reference with my older PC BlackThunder and believe me:
although it's very quiet by mainstream PC standards it's still by several orders of
magnitude louder than Blackbird (where you can only hear the harddrive at point
blank range near the front and back of the case, and that's way, way below
the noise level of even a good Papst fan). Anyone claiming a fan-based cooling
system was truly noiseless is either truly deaf or another clueless idiot who considers
himself an expert. The Zalman TNN case is the closest thing to a truly noiseless
system without considerable restrictions on flexibility and performance I know, and
without the hassles of watercooling (which is better suited for overclocking than noise
reduction); unless you've ever seen and heard one, don't bother to make comparisons.
An added bonus of the Zalman case is the phenomenal build quality (well, everything
except the screws, of course), this is a real man's case whose looks (and weight)
have more in common with a Krell power amp than a typical PC case which looks like
a cookie tin by comparison (yes, your cool Lian Li and HTPC cases too). The
big problem with the case is that it's quite hard to make it work with contemporary
components because things like fan mounts and motherboard layouts change all the
time, but the heatpipes are quite inflexible, so a lot of the time you need to
improvise. I certainly couldn't recommend the case to the average PC builder, let
alone the average PC user. But despite the rocky path that led me to the finished
product I'm quite happy with my new toy at this point (expense being the least factor,
actually), and I'm looking forward to a noiseless future (noise that doesn't come out
of my speakers, that is).
Oh yes, and in case you're wondering why I called it Blackbird, this is
of course in honour of the famous
Lockheed SR-71 "Blackbird"
strategic reconnaissance jet, which is also fast, black and extremely stylish, albeit a lot
louder than my Blackbird...
And for a minute there I thought the pain was over...
This is now several months later (november 2007) which had some really nasty
surprises in store for me. Although I thought I'd come to grips with Gentoo,
the first set of problems were software again.
Linux cryptography still run by retards
The first really nasty issue was the update of cryptsetup-luks from
version 1.0.3-r2 to 1.0.4-r3 I got in late june with my system updates. I saw the new
config file in /etc/conf.d and thought I'd adapted it correctly to my
configuration, but imagine my surprise when after the next reboot I couldn't mount my
encrypted home partition any more. I had another closer look at the config file and
realized I'd overlooked an important change of keywords,
namely mount had become target. So I adapted this, rebooted and...
still no luck. After several more failed attempts to mount the partition manually, I
tried downgrading the cryptsetup-luks and device-mapper packages, but
found out that this didn't work either because the new cryptsetup-luks startup
scripts (and with them the new parser) remained in /lib/rcscripts/addons/dm-crypt/
and were still active, so the downgrade actually resulted in a bizarre mixture of versions
1.0.3 and 1.0.4, so I upgraded to 1.0.4 again for consistency's sake. Following that, I
decided to just create the device-mapping manually and have a look at the contents of the
device mapper's pseudodevice for this partition. Provided the actual decryption worked and
the partition wasn't completely shot to hell, the contents should contain regular data,
otherwise pretty much random data. So I fired up less -f /dev/mapper/crypt-home
and lo and behold, this looked pretty organized, but obviously couldn't be mounted.
Next up I ran e2fsck on this device (it's an ext3-partition) in verbose
read-only mode (e2fsck -v -n) and its output looked pretty good. It reported
a plausible amount of regular files and directories and the amount of errors was
comparably small. The only thing that still irritated me was the number of blocks used
it reported (131528), which was way too small; but it looked like not all was lost.
Consequently, I made a backup copy of the entire partition and ran e2fsck with
write permission. I got pretty much the same results as in the read-only case, but at
the end the amount of used blocks was plausible as well and when I mounted the partition,
this finally worked (to my greatest relief), I couldn't find any obvious inconsistencies
and even lost+found was empty. So far so good, but what the fuck had happened???
After pondering the problem for a while, it suddenly hit me: the change of the mount
keyword in combination with one of the most braindead config-file parsers imaginable
caused this! Why? Well, as recommended I had first a swap partition and then my
encrypted home partition in the config-file. The "parser" (you really
have to laugh, calling this abominable piece of shit a parser) keeps track of
the sections for different partitions by the keywords starting new sections, namely
swap (unchanged) and mount (obviously changed). So what'll happen
if you run the 1.0.4 "parser" on a 1.0.3 config file containing the
"exotic" configuration of encrypted swap and encrypted home partition?
Well, it'll see the commands for a swap partition, but (sections being multi-line)
won't execute them until it encounters the next section or EOF. Since it now
expects target where the old config file specified mount, it'll
never encounter the next section, only EOF. This is the first critical blunder:
any program handling partitions HAS to terminate if it encounters a
syntactical error in its config files to avoid serious, irreversible damage,
and for the new parser mount would definitely be a syntactical error.
Now here comes the crux: not only does the parser not abort, it will even happily
accept all other options of the following sections (in particular source)
for the current section (swap) because obviously it's too much to ask from a
parser to realize something can't be right if it gets e.g. multiple source
specs for the same section (the next critical blunder); so when it finally reaches
EOF, it'll execute the commands for the only partition it identified, the encrypted
swap partition, which unfortunately now has the device for the encrypted home partition
as source. In other words: it'll create the encrypted swap partition on the device
holding your home partition! Good thing this system has 2GB of main memory, so I never
actually used any swap while I was dealing with this issue. I also have to say the robustness
of ext3 really impresses me, it even survived being turned into a swap partition
temporarily, that's quite a feat. Equally impressive, although in a wholly negative way,
is the unbelievable stupidity of the cryptsetup-luks maintainers:
- they changed a crucial keyword without thinking about the consequences this
would have for anyone who overlooked the config file changes during system updates
(very easily done, believe me, even if you noticed that there were changes in the
config file);
- despite changing the keyword, they didn't even think of extending the
"parser" far enough to just abort on a syntactical error, which
would have easily avoided disaster;
- the parser is also too retarded to abort on obvious semantical errors like having
multiple source specs for the same section. Again, this would have avoided
disaster.
I thought things had gotten better in the past couple of years, but apparently the
people involved in the Linux cryptography modules are still pretty much the biggest
bunch of morons to be found in the entire open source scene. In the 2.4 kernel
series, they made an incompatible change to the CryptoAPI from one minor kernel version
to the next (2.4.21 to 2.4.22, IIRC), without an official/guaranteed way of reading
old partitions with the new framework, thus making it impossible to migrate to the
newer framework without first copying all your encrypted data to an unencrypted
medium, which is completely unacceptable to anyone actually using cryptographic
storage rather than just playing around with it. And now this combination of
brainless maintainers and an equally brainless parser leading to a valid config
file for one version causing busted partitions for the next minor version--
it's really hard to believe how retards like this are allowed anywhere near software
development. And to all smartass backseat-drivers out there: I'm not
complaining that overlooking a change of config file causes the package not
to work correctly; I'm complaining that overlooking a change of config file
causes irreparable damage because there were no precautions whatsoever taken
to trap even the most obvious errors, although it should have been perfectly
clear that there's a certain likelihood that older config files might be encountered.
I don't have a problem with something not working due to an oversight on my part, but
which I can fix after I found the error; only having one chance to get it right
and having your partitions wiped if you don't get it right at first try is something
else entirely. Would anyone accept a change like this for fstab, no matter
what warnings are output during the system update? Fat chance. So I can only repeat:
fucking retards!
And while the major fault lies with the cryptsetup-luks maintainers, let's
not forget Gentoo either. The fact that something as fundamentally broken as this
cryptsetup-luks update made it through their "quality control"
by being unmasked is also a critical fault on behalf of this distribution. It
should have never been allowed in the stable packages unless the maintainers
added at least the most primitive attempts at error checking to their config file
parser. I sure hope the Debian crowd will be smarter than this.
The many consistency holes of Portage, part 239847
After this major annoyance, it was a comparably small issue when one day, I got the
odd freeze I described here when I started my regular
X-session, at which time I decided enough was enough and recompiled my entire system
to rule out inconsistencies. First up I checked my system for packages where the
USE flags had changed (emerge --newuse) in order to make sure they'd
still compile with the default flags on a system rebuild. I found a couple (some
actually leftover from my system installation) and where necessary adapted
/etc/portage/package.use, then triggered the rebuild
(emerge --emptytree system), which basically put the system in a 10 hour
stress test, but luckily there were no errors on the way. I found another
Portage oddity afterwards, though: some packages that weren't rebuilt (like vim)
didn't work anymore, complaining about what looked like a missing Perl symbol
on startup. A recompile fixed this, but seriously: how can rebuilding your
packages with the same USE-flags cause malfunctions like this? This
is simply impossible if the USE-flags are the only factor, so there
has to be something else Portage isn't telling me. Not even mentioning that
revdep-rebuild didn't find these problems, since apparently they only
manifest when you actually run the programs rather than just ldd them;
the bogus GCC-inconsistencies are still reported by revdep-rebuild
in november 2007, though: this bug is nearing its second birthday with no end
in sight! And a sudden appearance of build failures for packages with USE=doc
had to be fixed by re-emerging sgml-common (BUG-196605, again no change
of USE-flags). Portage is increasingly looking like a joke, really.
Of broken motherboards and RMA procedures
All of this pales compared to the hardware problems that manifested near the end
of july, however. When I switched on the machine one day, it ran for about 3 seconds,
spinning up the drives, and then immediately switched itself off again without
even giving me a chance to enter the BIOS. When I repeated this process enough
times I managed to get the machine to POST and boot and once the OS was up and
running, everything was perfecly stable even under extreme load. Some will
indubitably be quick to claim I fried my hardware, but a) how would that be
possible considering the temperature readings I made under load and b) assuming
something overheated, how can the machine run stable under load? Naturally,
this problem didn't just go away, and in addition I found that the system
clock was going rather mad: the BIOS clock seemed to show the time of the
last boot or something like that, not the current time, and after booting
the OS the time was usually far into the future (in the end something
like the year 2038). Additionally, I found I couldn't access the hardware
clock with hwclock, not even read it. CMOS settings were still as I
left them, though, even if switched off the PSU completely; I nevertheless tried
replacing the CMOS battery and also clearing the CMOS RAM for good measure, but
had no luck with either. So I contacted QuietPC's Andy Ford, who once again
was very helpful, said it might be the PSU and contacted Zalman to send
me a replacement unit. I was sceptical about this because I'd had broken PSUs
before and they usually don't fire up at all rather than keep the machine running
for 3 seconds and take the drive spinup load, only to shut down afterwards, but since
exchanging the PSU was one of the simpler things to try I couldn't see any harm
in starting with this. Imagine my surprise when hardly a week later I had an
express parcel from Korea with the new PSU in my mailbox (free of charge). I
thought I'd have to wait a month before I'd get the replacement PSU; kudos the
Zalman, this is really highly impressive stuff (although I also doubt you
can expect this kind of service for cheaper components...). So I built in the
replacement PSU, switched on and... same problem. "Of course," I might
add, since naturally that would have been far too easy and I've obviously had such
a "smooth" ride with this machine so far. Just my luck...
With the PSU out of the equation, that basically left the motherboard as prime
suspect, in particular in light of the clock oddities on one hand and the perfect
system stability if the machine survived the boot process on the other. The mere thought
of replacing the motherboard made me sick to my stomach, considering that the motherboard
is a lot of work to exchange even in a normal system, and it's a lot more work
in a TNN case due to the heatpipes and most of all the rear-mounted cooling blocks
(the latter being one-way due to their thermal pads). Still, the motherboard had
to go first, so I took on the arduous task of removing it from the TNN case one
afternoon. This proved less of a problem than I had feared, though. Getting the CPU
block off is a bit fiddly since thermal paste and pressure give it a rather strong
suction to the CPU, but if you twist it a little here and there it'll come
off without major problems. Removing the graphics card is pretty easy as well if you
do it right: only open the heatpipe block on the case, then remove the card
with its entire heatpipe assembly (which naturally includes the heatpipes).
As far as the rear-mounted cooling blocks are concerned, it became obvious why
they're one-way, with the thermal pads partly sticking to case/block/motherboard
and generally speaking in no state that encourages reuse. That done, I filed an
RMA with the dealer (HIQ24), at length describing
the problem (switch off before POST, clock going haywire) and dispatched the
package. I got a confirmation very quickly, but the fault description there was
completely wrong ("board crashes and freezes occasionally"); I addressed
this and asked for clarification but never got an answer. Then about 5 weeks passed
without hearing anything about the board either. I used this time to find ways to reuse
the rear-mounted cooling blocks, which basically meant finding replacement thermal
pads which are thick enough and adhesive on both sides (unfortunately, Andy Ford
couldn't help me with these). As I came to realize, these are practically impossible
to find. The closest thing were Aquacomputer Ramplex pads which are about
1mm thick, but only adhesive on one side; still, I figured there'd always be ways
to glue the other side, so I ordered a bunch or those (with enough spares for
2 motherboards). When I finally got the board back, there was the next oddity:
no repair report, which I'd expect from any decent repair shop. Unfortunately
I didn't have the spare components to actually test the motherboard without the
extreme amount of work required to put the board into the TNN case, so due to lack
of less work-intensive alternatives I took a deep breath one sunday afternoon and
reassembled Blackbird. The biggest problem were the rear-mounted cooling
blocks, as expected, since I found out that the Ramplex pads aren't really adhesive
on either side, certainly nowhere near enough to hold the blocks in place during motherboard
installation. I experimented around with thermal glue and duct tape, where in
hindsight the thermal glue was definitely a bad idea because that requires rigid
components to work, whereas the pads are flexible, which causes the connection to
break at the slightest bending. In the end, I got everything in place, largely
thanks to the duct tape, and once the motherboard was in place, the rest was quite
easy (including the graphics card: if you removed it like I described
above, all it takes to put it back in is basically adding thermal grease to the case
block and sticking it back in). After something like 4 hours of very fiddly work, the
machine was assembled again, and I hit the power button. It lit up, the drives
spun up, and after about 3 seconds the machine switched off again.
What the FUCK?!?
In the following days, I tried various things without effect: removing all drives,
removing the front-panel connectors etc., but none of these fixed the problems.
I thought I'd hit something when the machine booted again after I'd removed all
front panel connectors, but when I tried again with the same configuration the
next day, it was dead again. Little remark re. Gentoo: with all the delays
involved, I had almost two months worth of system updates in the queue when I
acutally managed to boot the system eventually, resulting in about 700 MB of
downloads and around 7 hours of non-stop compilation for the updates; just to
give people an idea about the update volume and time, should they consider
using Gentoo. The system clock was still going cucko when I got the machine
up and running, which fueled the suspicion that the board was still broken.
Without spare parts to test everything else, there was little I could do save
for either buying a minimum set of spare parts (graphics card, CPU, RAM) or
buying a new motherboard and trying whether that would work with the
existing components. I also searched the web for problems reported for
the Asus M2N-series motherboards and came up with quite a few hits
where people had exactly these symptoms across the entire range, so it looks
like Asus really messed up with these boards. Consequently, I chose trying
a replacement motherboard first, partly because it was still by far the most
likely candidate judging by the symptoms of my board and other peoples'
boards, and partly because a new motherboard was also the cheapest route
(albeit the most work-intesive by a long shot). Since I wanted a smooth
transition without having to reinstall a new kernel from a LiveCD just to
get the board running, I chose one with the same chipset (nForce 570)
but naturally avoided anything Asus like the plague. I eventually
picked a Gigabyte GA-M57SLI-S4, which lacked some of the things the
Asus board had, but I either didn't need those anyway (like a second
ethernet port) or they could easily be addressed with a bracket (like an
E-SATA connector); it did have one thing I needed onboard, though, which is
a parallel port, thus all in all I gained about the same I lost. The board
was also rather inexpensive (80 Euros in September 2007), so there wasn't
much to lose (apart from my work hours, of course). Putting in the board
went slightly faster than the last time, but not by much, since the
rear-mounted cooling blocks still took a lot of work because most of them
still relied on thermal glue which came lose when I removed the Asus
board. But this time around I was smarter and did everything with duct tape,
ensuring that the thermal blocks will be far easier to reuse in the future
(may that day be many years off!). There was a nasty surprise regarding
the CPU cooler bracket, which in contrast to the Asus board wasn't screwed
in but held in place with some plastic contraption (which can be removed
in a reversible manner, fortunately), so I couldn't use my
Socket939-adapter unless I used the backplate of the Asus-board -- which
I couldn't do, since it was clear that if the new board worked, the
Asus-board would go back. I lucked out on that count, though, since
rummaging through my "unused small parts and other junk" collection
I found some of these things which look like the head ends of screws, but have an inner
thread opposite the head, which fit the adapter's screws like a dream and were
just the right length, at least after adding some thick rubber which I needed as
insulation anyway. What I'd feared would become a haphazard construction thus
turned into a basically perfect fit. Maybe a few additional words on the board
layout are called for: some things are better than on the Asus board
(like the location of the IDE-connector and everything's less cramped), some
things are worse (like the location of the floppy drive connector at the
bottom of the board, the front panel audio connectors at the back, or the
screwholes of the motherboard, where the third column doesn't match the
case's mounts -- I thought ATX clearly specified that kind of thing...?), so
once again I lost about as much as I gained. The northbridge heatsink is a bit
close to the graphics card, but on the other hand I think there may even be
a way to connect the northbridge heatpipe this time. At the time
of writing, the floppy drive still isn't connected because I lack a cable
long enough to reach there and survive the opening of the TNN case, but that'll
soon be fixed. The most important thing is: when I switched the machine on,
it started right away, it booted into Linux just fine (apart from some clock
and network interface issues I'll go into below) and it hasn't shown any
signs of instability yet. So it should be pretty clear now that the Asus
board was indeed still broken, the RMA-procedure just another hoax. I then made
a mental list of my RMA-procedures in the past 5 years and came up with the
following:
- Plextor PX-W4012A (warranty, 25 Feb 2003): got working replacement drive
free of charge
- Unicomp Customizer Keyboard (warranty, 10 Apr 2003): got working replacement
for DOA keyboard, free of charge
- SilentMaxx PSU (warranty):
- (21 Apr 2004): "repaired" PSU, DOA.
- (14 May 2004): repaired PSU, now working
- Plextor PX-W4012A (warranty):
- (2 Nov 2004): got replacement drive free of charge, DOA
- (12 Nov 2004): got replacement drive free of charge, DOA
- (25 Nov 2004): got replacement PX-W52/24/52A free of charge, finally working.
- Zalman TNN-500 PSU (warranty, 13 Jul 2007): got replacement PSU free of charge,
working.
- Asus M2N-SLI Deluxe motherboard (warranty):
- (25 Sep 2007): got "repaired" motherboard after 5 weeks, DOA
- to be continued
Should any companies and their lawyers feel unfairly treated by this list, let me
assure you I still have all the documents for these RMA-procedures on file, so if you
want to make a fuzz over this, go right ahead. Anyway, what does this list tell us?
Half of the six cases ended up with DOA components sent back to me, this can
hardly be explained by coincidence or sloppy work, there's definitely a method to
this madness. Since customer time is obviously worth nothing to most big companies,
they'll first try to send you back any old crap and leave you to sort out whether
it actually works or not. If it still doesn't, there's a good chance the customer
will just give up, throw it away and try to fix things some other way; otherwise they'll
maybe have their first serious look the second time you try it. Unfortunately,
this strategy appears to work, rendering the whole RMA process a huge farce. I'm
also sorely tempted to just throw the board away, but after the above RMA history
and the hours of my time the dud motherboard wasted I now have a very keen
interest to see this through to the bitter end, far beyond the actual worth of the
motherboard. Even though I'll have to build another computer just to prove whether the
board finally works or not (since there's absolutely no way I'll dismantle Blackbird
in its current incarnation as long as it works), I won't let this outrage go
unanswered. Congratulations, you bastards, now it's personal!
I'd also like to add that it's a very sad day for german customer service if it takes
5 bloody weeks to get back a broken motherboard (which I also had to pay postage for)
where Zalman managed to send a working replacement PSU from Korea within a week,
free of charge, no questions asked.
Further software issues to sort out
There were also some minor and a critical problem on the Gentoo/Linux side I
encountered while setting up the new motherboard (naturally). First up I didn't
get an ethernet connection, which rather amazed me, since the chipset (including
the network chips, or at least their interface) should be the same for the
Asus and Gigabyte boards. I also still had a broken clock and still
couldn't read it with hwclock for some odd reason, but at least the clock
shown in the BIOS screen was correct. Speaking of the BIOS, a short word of warning:
don't press DEL before the board's startup screen shows, it'll hang (that
caused another nasty shock the first time it happened to me; because the time slot
for pressing the key is usually very short and since the monitor synchronizing to the
signal change can further reduce this tiny window to practically nothing, I made a
habit out of holding down the key right after powerup if I want to enter the BIOS).
As far as the network and clock issues were concerned, I suspected minor incompatibilities
between the two motherboards at first and decided to build a "fat" 2.6.22
kernel with basically everything related to network and clock drivers available as
modules. I also added more libata drivers and network filtering modules in
the process (nothing experimental, though), but when I tried rebooting with this
kernel, I got a kernel panic right at the start -- how great, things are starting
really well once again, aren't they? In hindsight, I should have kept the kernel
config file and created a bug report, of course, but at the time I just wanted to get
everything working again, so I cleaned the kernel, copied my working 2.6.20 config
over to 2.6.22 and this time only added network and clock drivers. And finally,
I could boot this new kernel. Network still wasn't working, clock was still wrong
and couldn't be accessed, though; I saw mention of net.eth2 in the boot
output, however, which had hitherto escaped me, so now it was clear what had
happened to my network: apparently the udev infrastructure automatically
creates network devices via MAC-addresses (of which the Asus-board had two) and
since the Gigabyte board has a different MAC-address, it got assigned the next
available net.eth device. After adapting my config-files for net.eth2,
I had a working network again. The clock issue disappeared in a similar manner:
I still had chronyd running per default and while it's running you can't
access the hardware clock (plain and simple). In addition, the clock problems of the
Asus board had totally screwed up its drift values, so in effect as soon
as chronyd was started, it "corrected" the system clock to some
completely insane values in the far future. You'll have to stop chrony,
wipe the files in /var/lib/chrony/, set the clock manually to the correct
time and then everything will finally work again.
Everything? Well, of course not. When I shut down the machine after all of this,
content with having everything up and running again, I got a kernel crash while
shutting down Alsa, in the hdsp-driver module! Now that's a really
nasty shock, I can tell you. The next day I tried accessing the Hammerfall-card
with amixer, but as soon as I tried reading anything from there, the
amixer-processes hung hard (no way of killing them). So
I cursed, shut down the machine (which this time "just" hung indefinitely
while stopping Alsa and once again went to bed with problems on my mind.
Since the machine now worked correctly again even with kernel 2.6.20 (after network
and clock problems turned out to be caused by other factors), at least I could
finally use the machine after all this time. I searched the web and found that other
people had this problem as well, which by the looks of it was caused by recent changes
to hdsp.c, and some apparently managed to fix it via a firmware upgrade
to 1.52 (which, as you may remember, was still completely unsupported and had to
be downflashed to 1.51 in a Windows machine for the Alsa drivers available
at the time I got this card). Since I didn't want to get stuck with the 2.6.20 kernel
(the way I was stuck with the 2.4.21 kernel on bthunder due to CryptoAPI
changes), I decided to file a bug report on the Gentoo Bugzilla (BUG-196612), which
quickly traced the problem to an uncaught division-by-zero in the hdsp-driver
and was resolved with a patch which should appear in gentoo-sources-2.6.22-r10
and upstream soon (both the official kernel sources and the offending Alsa-version
1.0.14).
So will the pain ever end?
Good question, I'd really love to get an answer to this before the next problem
hits me unawares. Needless to say, this episode reduced my trust in this machine
considerably (and just at the time when I finally felt comfortable enough with it
to make it my main computer) and it'll have to run flawlessly for a long time to regain
that trust, although it looks like the broken motherboard was just my bad luck picking
it from a misdesigned series of Asus boards and had
nothing to do with the TNN case. It also made DIY system building a whole lot less
attractive as well, considering how hard it can be just to identify the cause of the
problems if you don't have spare parts for at least a core system handy (which I didn't
have and I think people who don't build at least one system per year don't have either).
Only time will tell whether things will finally settle down for Blackbird,
but at this point I'm so sick and tired of problems around this machine
(and Linux development as demonstrated by cryptsetup-luks and the
hdsp driver) that I'm really beginning to wonder why I bother with all
this crap and don't just buy Windows machines from grocery stores like everybody
else. That coming from me says a lot...
Last updated: 7 Nov 2007
Back to my private homepage.